🎉 [2026-01-30]: Our paper has been accepted by ICLR 2026! 🎉 🚀 [2026-01-30]: We open-sourced the code and dataset! Check out our GitHub repo and 🤗 Hugging Face dataset! 🚀 🚀 [2025-06-05]: We release the Swing-Arena! 🚀
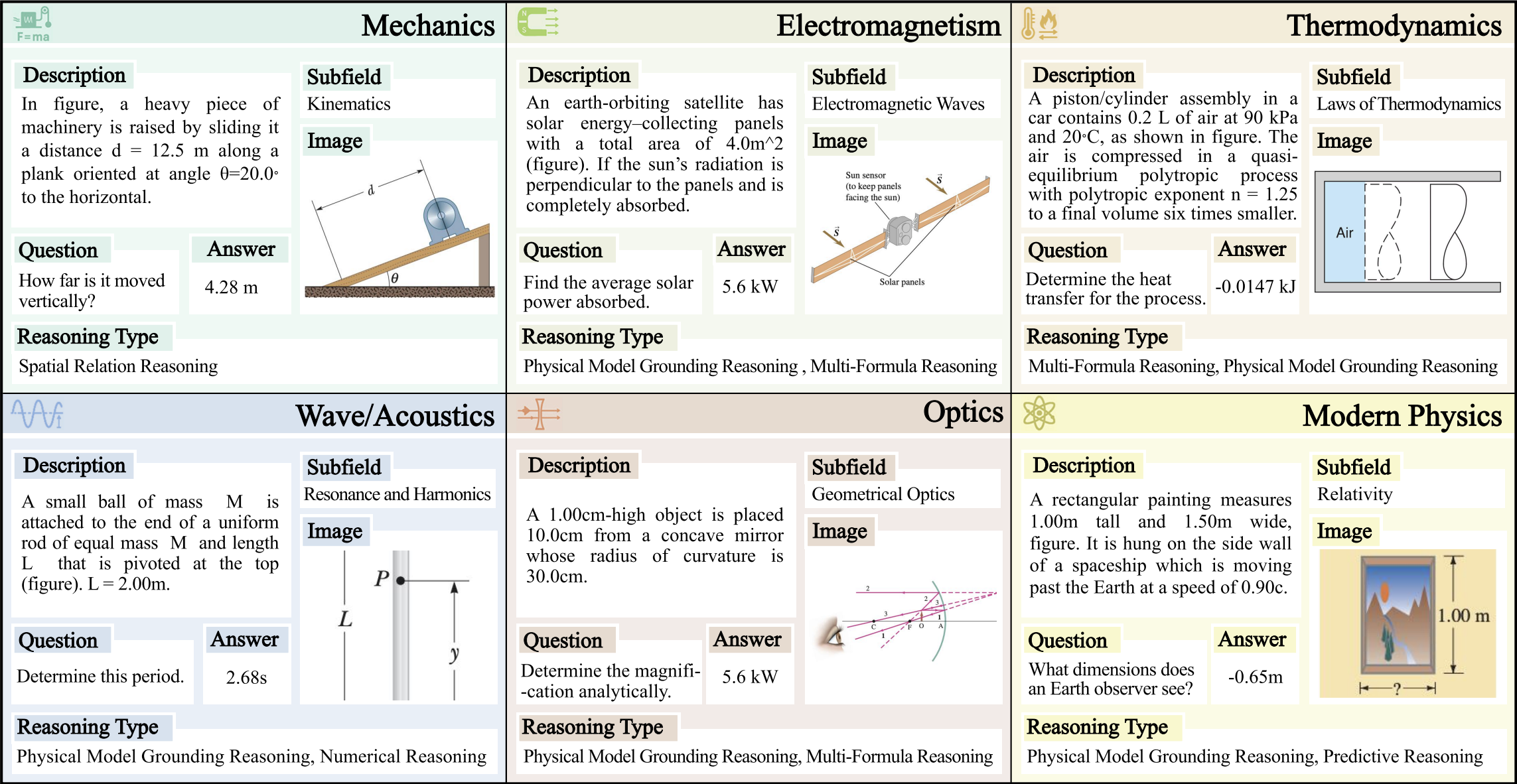
We present SwingArena, an adversarial evaluation framework for Large Language Models (LLMs) that approximates real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that handles long-context challenges by providing relevant code snippets from large codebases across multiple programming languages (C++, Python, Rust, and Go). Our adversarial evaluation can surface limitations that are often overlooked by traditional evaluation settings. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, indicate differing behavioral tendencies across models in patch generation versus validation. SwingArena offers a scalable and extensible approach to evaluating LLMs in CI-driven software development settings.
The data construction pipeline for Swing-Arena consists of several key stages, including repository collection, pull request extraction, task instance creation, quality filtering, and multiple CI-based validation.
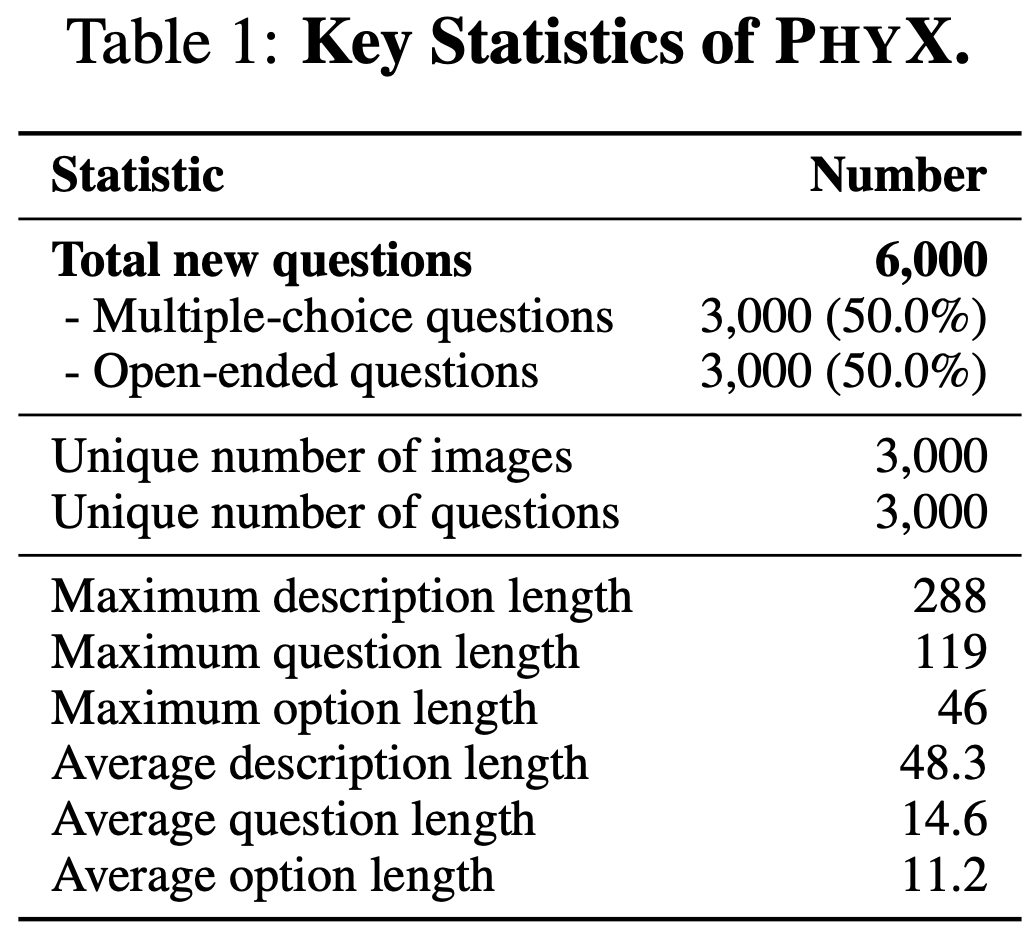
Clarity and Difficulty Distribution
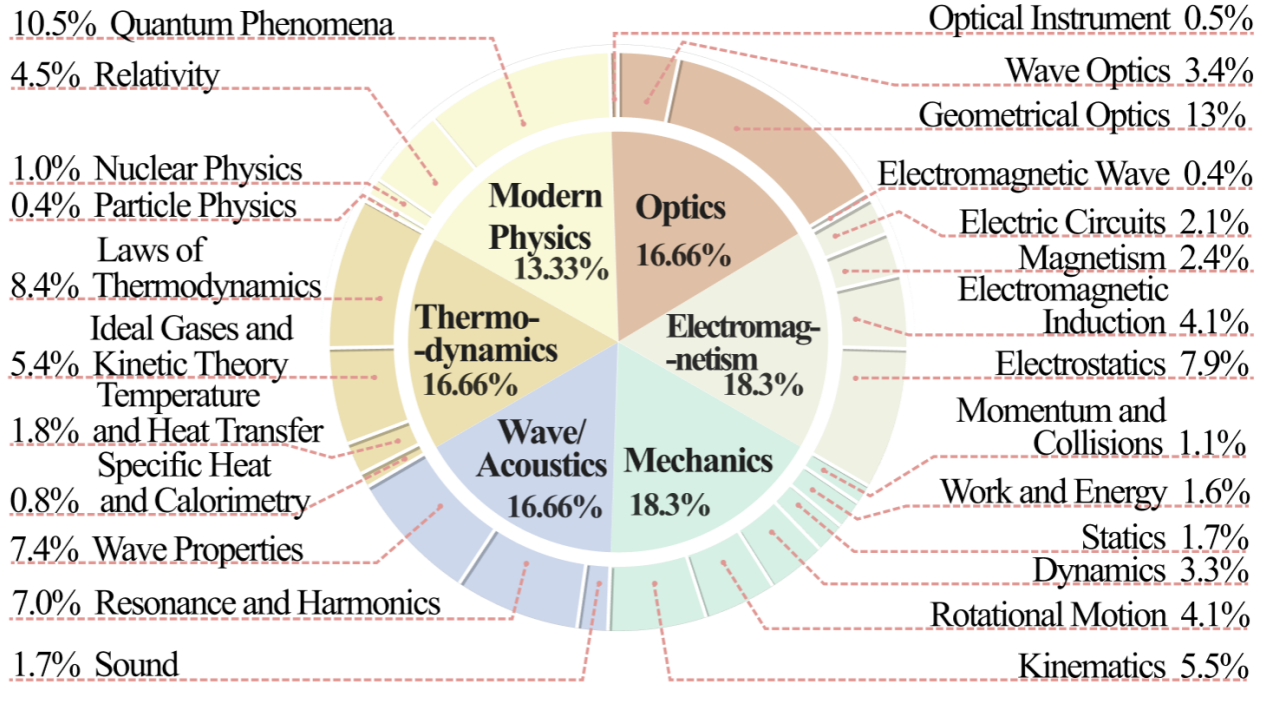
Length distributions in different languages
| Matchup | Submitter | Reviewer | RPR | SPR | Win Rate |
|---|---|---|---|---|---|
| ChatGPT vs ChatGPT | ChatGPT | ChatGPT | 0.71 | 0.68 | 0.97 |
| ChatGPT vs Claude | ChatGPT | Claude | 0.65 | 0.55 | 0.90 |
| ChatGPT vs Gemini | ChatGPT | Gemini | 0.61 | 0.55 | 0.94 |
| ChatGPT vs DeepSeek | ChatGPT | DeepSeek | 0.61 | 0.55 | 0.94 |
| Claude vs ChatGPT | Claude | ChatGPT | 0.66 | 0.55 | 0.89 |
| Claude vs Claude | Claude | Claude | 0.62 | 0.62 | 1.00 |
| Claude vs Gemini | Claude | Gemini | 0.59 | 0.55 | 0.96 |
| Claude vs DeepSeek | Claude | DeepSeek | 0.64 | 0.54 | 0.90 |
| Gemini vs ChatGPT | Gemini | ChatGPT | 0.61 | 0.55 | 0.94 |
| Gemini vs Claude | Gemini | Claude | 0.60 | 0.56 | 0.96 |
| Gemini vs Gemini | Gemini | Gemini | 0.72 | 0.63 | 0.91 |
| Gemini vs DeepSeek | Gemini | DeepSeek | 0.64 | 0.64 | 1.00 |
| DeepSeek vs ChatGPT | DeepSeek | ChatGPT | 0.60 | 0.55 | 0.95 |
| DeepSeek vs Claude | DeepSeek | Claude | 0.60 | 0.55 | 0.95 |
| DeepSeek vs Gemini | DeepSeek | Gemini | 0.68 | 0.64 | 0.96 |
| DeepSeek vs DeepSeek | DeepSeek | DeepSeek | 0.70 | 0.66 | 0.96 |
Evaluation of Code Submission vs. Test Submission Capabilities Among Proprietary LLMs.
@article{xu2025swingarena,
title={SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving},
author={Xu, Wendong and Xiong, Jing and Zhao, Chenyang and Chen, Qiujiang and Wang, Haoran and Shen, Hui and Wan, Zhongwei and Dai, Jianbo and Wu, Taiqiang and Xiao, He and others},
journal={arXiv preprint arXiv:2505.23932},
year={2025}
}